I analyzed my website through LLMs - OpenAI API integration


Introduction
LLM APIs has made so many things possible today. The integration simply makes it possible to speak to the LLMs like never before and perform and automate so many tasks for us. We can integrate it to summarize documents, ask questions, perform chat completions, generate images, and n number of other things.
This blog explores such an application of ChatGPT API to summarize my website in just 1-2 lines per blog. The steps involve reading all the blogs in my website web scraping techniques. Post reading my blogs into my dataframe, then I ask LLM to summarize my blogs into 2 just lines. Post this, I model my summary through Topic Modelling through tf-idf and vectorization approach - to provide a topic to my blogs.
Introduction to the concepts, approach and models I have used
Firstly, I have read my blogs from my website through web scraping:
Web Scraping: Web scraping automatically extracts content from a website. For my purpose, I have extracted blog titles and content from my website. I have used requests for fetching pages and BeautifulSoup for parsing and extracting the relevant information.
Post web scraping, I have summarized all my blogs using GPT 3.5 Turbo model of OpenAI.
gpt-3.5-turbo: GPT-3.5 Turbo is an advanced language model developed by OpenAI. It is a faster and cheaper variant of GPT-3.5, designed to generate high-quality text and understand complex prompts. While it maintains a strong ability to perform natural language processing tasks—like writing, summarizing, translating, and coding—it is optimized for efficiency and cost-effectiveness in production applications.
Furthermore, I have performed topic modelling to extract major patterns and concepts in each of my blog.
Topic modelling: Topic modeling is a technique in natural language processing (NLP) used to automatically discover the hidden themes or topics that occur in a collection of documents. Imagine you have a large set of articles, blog posts, or tweets. Instead of reading through all of them, topic modeling helps you find patterns in the words they use — grouping documents that talk about similar ideas, like "sports," "technology," or "health."
Lastly, I have parsed the summary created by GPT model into DALL-E foundation model so as to create an image that describes my blog.
DALLE: DALL·E is a powerful AI model that generates images from text descriptions. You type what you imagine—like "a futuristic city made of glass floating in the clouds"—and DALL·E creates a picture of it!
Results
Let me break this down into simple steps so if anyone has to replicate something similar.
Step 1: read the blog titles through web scrapping.
import requests
from bs4 import BeautifulSoup
def fetch_posts(tag, base_url="https://analytics-with-anurag.com", limit=10):
url = f"{base_url}/tag/{tag}/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('article', class_='post-card', limit=limit)
results = []
for article in articles:
title_tag = article.find('h2', class_='post-card-title')
link_tag = article.find('a', class_='post-card-content-link')
title = title_tag.text.strip() if title_tag else "No title"
relative_link = link_tag['href'] if link_tag else "#"
full_link = f"{base_url}{relative_link}"
results.append((title, full_link))
return results
# Get blogs and book reviews
blogs = fetch_posts("blogs")
book_reviews = fetch_posts("book-review")
# Display them
print("=== BLOGS ===")
for i, (title, link) in enumerate(blogs, 1):
print(f"{i}. {title}\n {link}")
print("\n=== BOOK REVIEWS ===")
for i, (title, link) in enumerate(book_reviews, 1):
print(f"{i}. {title}\n {link}")
Result: all my blogs are read through along with the titles.

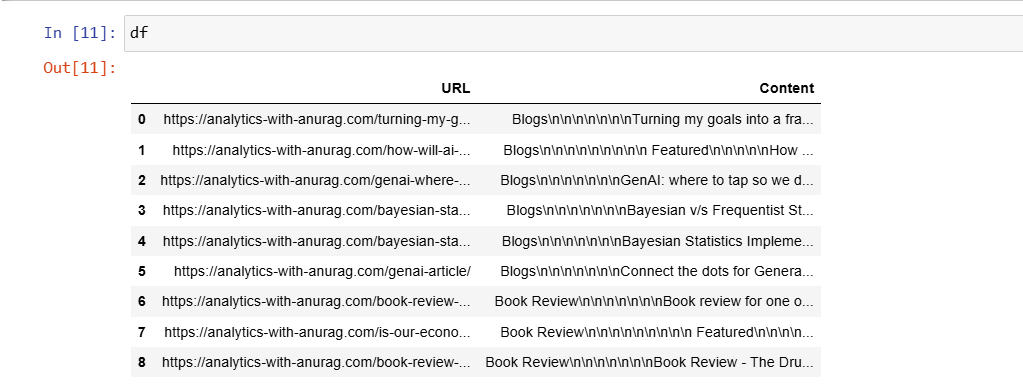
Step 2: Similarly, I read the content within each of my blog and then save all the information in a dataframe.
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_post_links(tag, base_url="https://analytics-with-anurag.com", limit=10):
url = f"{base_url}/tag/{tag}/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('article', class_='post-card', limit=limit)
links = []
for article in articles:
link_tag = article.find('a', class_='post-card-content-link')
if link_tag and 'href' in link_tag.attrs:
relative_link = link_tag['href']
full_link = f"{base_url}{relative_link}"
links.append(full_link)
return links
def fetch_post_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Try to find the content in a specific div or article
content_div = soup.find('div', class_='post-full') # Target the correct class
if not content_div:
content_div = soup.find('article') # Fallback to article
if content_div:
return content_div.get_text(separator='\n').strip()
else:
return "Content not found"
# Fetch blog and book review links
blog_links = fetch_post_links("blogs")
book_review_links = fetch_post_links("book-review")
# Combine all links
all_links = blog_links + book_review_links
# Fetch content for each link
data = []
for url in all_links:
content = fetch_post_content(url)
data.append({'URL': url, 'Content': content})
# Create DataFrame
df = pd.DataFrame(data)
# Example: Access content of the first article
print(df.loc[0, 'Content'])
Result: All my blogs are read through in the below format.
Step 3: Use Open AI integration and prompt the GPT model to summarize the content of the blog in 1-line.
import os
import openai #needed for error handling
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
import os
os.environ["OPENAI_API_KEY"] = "PUT YOUR KEY HERE"
# Initialize the OpenAI client
client = openai.OpenAI(api_key=os.environ["OPENAI_API_KEY"])
from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI()
# Define a function to summarize the blog content
def summarize_blog_content(blog_content):
completion = client.chat.completions.create(
model="gpt-4o", # Use GPT-4 or any available model
messages=[
{
"role": "user",
"content": f"Summarize the following blog content in most intelligent way possible in 1 line: {blog_content}"
}
]
)
# Return the summary
return completion.choices[0].message.content.strip()
Above function asks GPT model and prompts it to summarize the blogs in just 1 line. We use ChatCompletions function of the OpenAI GPT model.
I need to summarize each blog - so in below step, I have passed each of my blog into the above function as a parameter.
# Assuming you already have your DataFrame 'df' with the blog content
# Create an empty column 'Summary' in the DataFrame to store summaries
df['Summary'] = ""
# Loop through each row in the DataFrame and call the summarize_blog_content function
for index, row in df.iterrows():
blog_content = row['Content'] # Get the content of the blog
summary = summarize_blog_content(blog_content) # Get the summary for the blog
df.at[index, 'Summary'] = summary # Store the summary in the 'Summary' column
# Print the DataFrame to see the summaries added
print(df)For example: OpenAI summarizes one of my blogs which talks of my learning frameworks as:

Step 4: Extract common theme for the blog content through topic modelling
I have used the concept of tf-idf (term frequency, inverse document frequency) to assess the common themes in my blog content. Note - I have not used any LLM for this step.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
# Step 1: TF-IDF on your blog summaries
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=1000)
tfidf = tfidf_vectorizer.fit_transform(df['Content'])
# Step 2: Fit NMF
nmf = NMF(n_components=5, random_state=42)
nmf.fit(tfidf)
# Step 3: Get topic keywords
feature_names = tfidf_vectorizer.get_feature_names_out()
topics = [
", ".join([feature_names[i] for i in topic.argsort()[:-4:-1]])
for topic in nmf.components_
]
# Step 4: Assign topics
doc_topics = nmf.transform(tfidf)
df['topic'] = doc_topics.argmax(axis=1)
# Step 5: Create better topic sentences
# Instead of using `topics[x].split(', ')`, we'll use the top words directly from the NMF components
df['topic_keywords'] = df['topic'].apply(lambda x: f" {', '.join([feature_names[i].title() for i in nmf.components_[x].argsort()[:-6:-1]])}.")
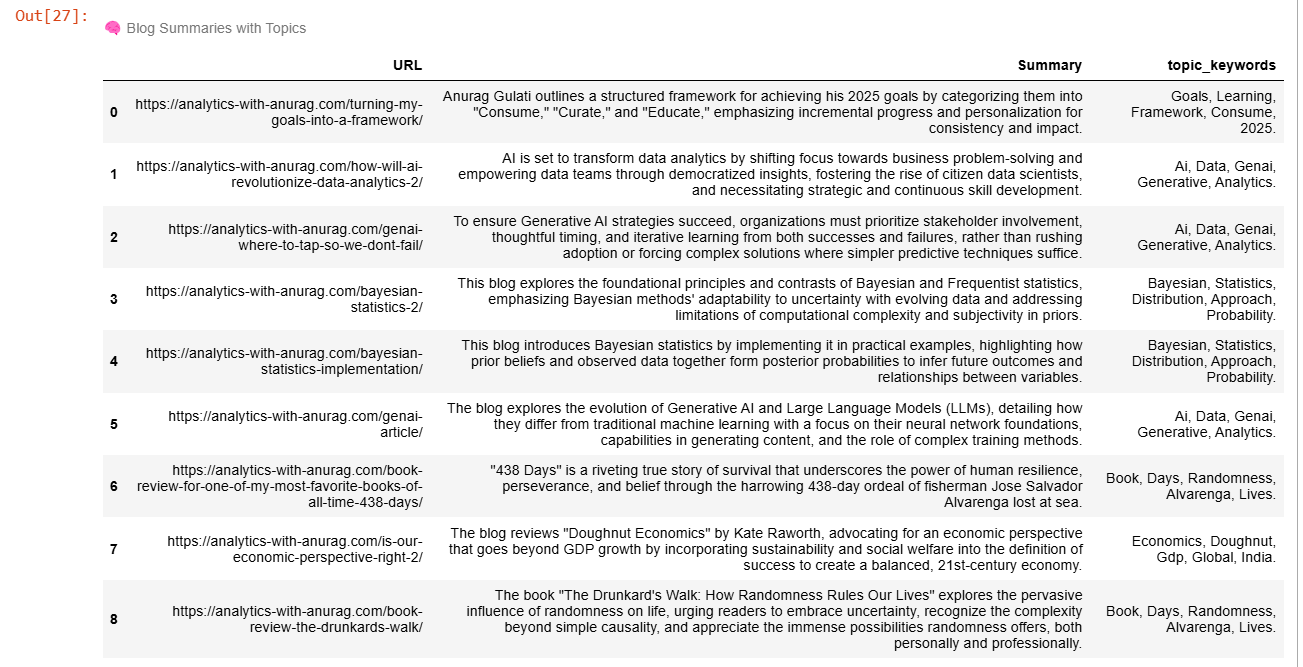
df_temp = df[['URL','Summary','topic_keywords']]
df_temp.style.set_table_attributes("style='display:inline'").set_caption("🧠 Blog Summaries with Topics")
Here is my final summary: summary is the 1-liner summary of each of my blog. The topic-keywords are the result of topic modelling and tell us about the common themes that my blogs speak about. For example: the blog about my 2025 goals and learning frameworks - have modelled topics:
Goals, Learning framework, Consume, 2025.... This is precisely what I was mostly talking about in my blog! These topics can become my hashtags.
I also did one more step - generated images to summarize my blogs through DALLE integration. However, I am skipping that part for now as it works very similar.
What does this mean?
Isn't this very powerful? APIs of the foundation models have made it possible to enable immense use cases - for both structured and unstructured data.
Below are some of the top use cases for these integrations:
- Content Generation: Blogs, emails, social posts, summaries
- Customer Support: Chatbots, ticket classification, smart replies
- Data & Analytics: NL-to-SQL, report summaries, data explanations
- Knowledge Management: Semantic search, document Q&A
- Coding Assistance: Code generation, debugging, auto documentation
- Enterprise Productivity: Meeting notes, email summaries, task extraction
What this really means is that we are going to re-image the world in next few years. A lot of things that we used to do will be commoditized and will be made easier. For example: data & analytics industry will see this shift wherein writing codes will not be rewarded, rather more strategic problem solving, and approach will have much more value in the future. Similarly, content generation will become so much easier.
What I have really seen in terms of the AI enablement is the attitude shift. Currently, there is too much rush. Innovation is encapsulated into the bubble of using AI - sometimes forcefully, rather mostly forcefully. However, in future, the development of tools, frameworks and functions that use foundation models to enable use cases will be very common. The winners will be those who will focus on the problems - because it is very important to solve the right problems with a net positive upside, instead of wasting time on executing numerous POCs.
Also, to a certain extent, it is very important to be a part of this evolution, irrespective of the use case we are testing out, because it makes us realize, what a significant shift we are heading towards.